Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. #
Mixture-Of-Experts #
现在的模型越来越大,训练样本越来越多,每个样本都需要经过模型的全部计算,这就导致了训练成本的平方级增长。
为了解决这个问题,该文章提出了 Mixture-Of-Experts (Moe,稀疏门控制的专家混合层),将大模型拆分成多个小模型。对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算,这样就节省了计算资源。
那么如何决定一个样本去经过哪些小模型呢?这就引入了一个稀疏门机制,即样本输入给这个门,得到要激活的小模型索引,这个门需要确保稀疏性,从而保证计算能力的优化。
模型结构 #
MoE是一个层,而不是一整个模型。这个模型结构包含一个门网络来决定激活哪个expert,同时包含n个expert网络,这n个expert网络一般是同结构的。
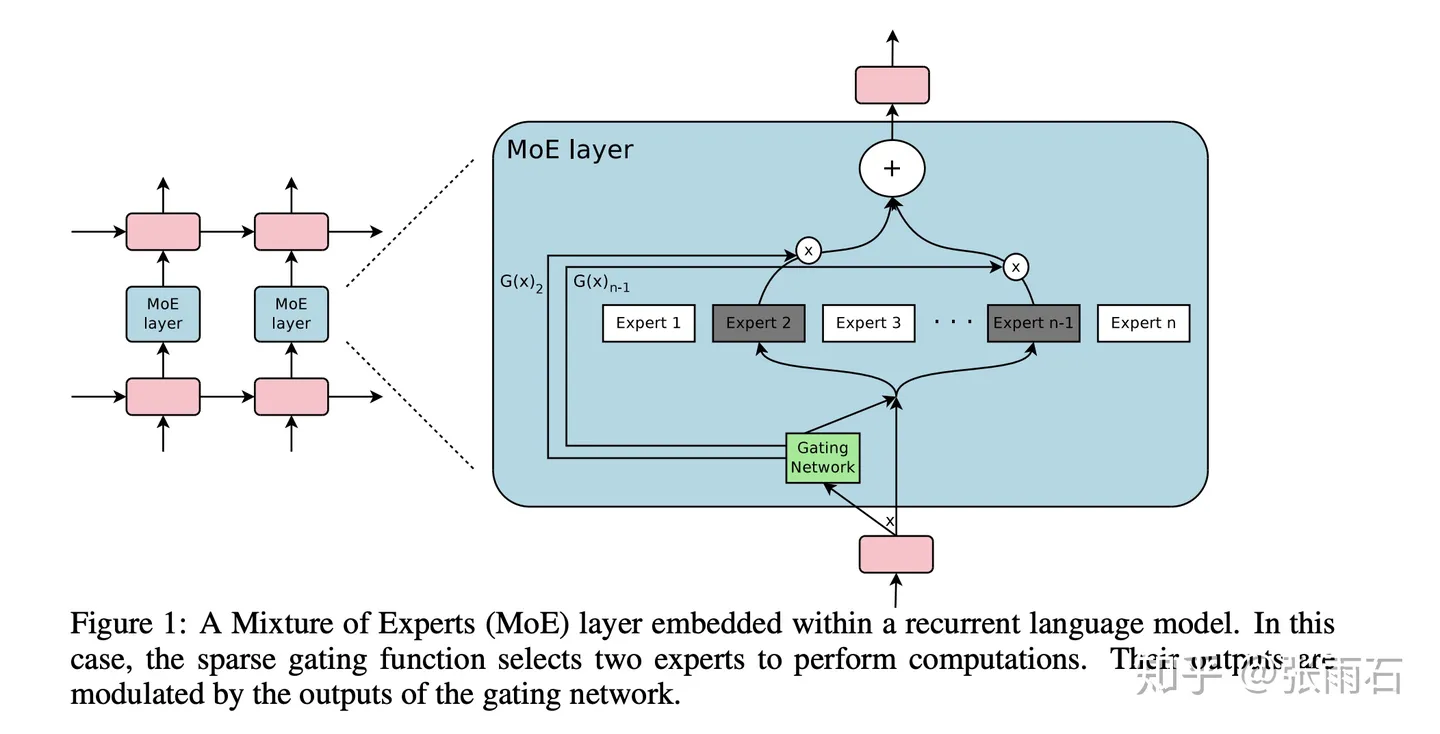
这个门网络其实比较简单,就是一个dense layer再来一个softmax。 $$ G_\sigma(x)=\text{Softmax}(x\cdot W_g) $$ MoE层的输出如下,当$G(x)_i=0$的时候,对应的 expert 就不会激活。 $$ y=\sum_{i=1}^{n}G(x)_iE_i(x) $$
Hybrid hierarchical learning for solving complex sequential tasks using the robotic manipulation network ROMAN #
Overview #
该文章提出了一种混合分层学习 (hybrid hierarchical learning,HHL)框架:机器人操作网络(ROMAN),用于解决复杂的机械臂长期操作任务问题。ROMAN 结合了 behavioural cloning, imitation learning and reinforcement learning。它由一个中央操作网络(manipulation network,MN)组成,用于结合和编排包含各种神经网络的集合,每个网络用于为不同的可重新组合的子任务生成正确的连续动作 (High-level task decomposition)。
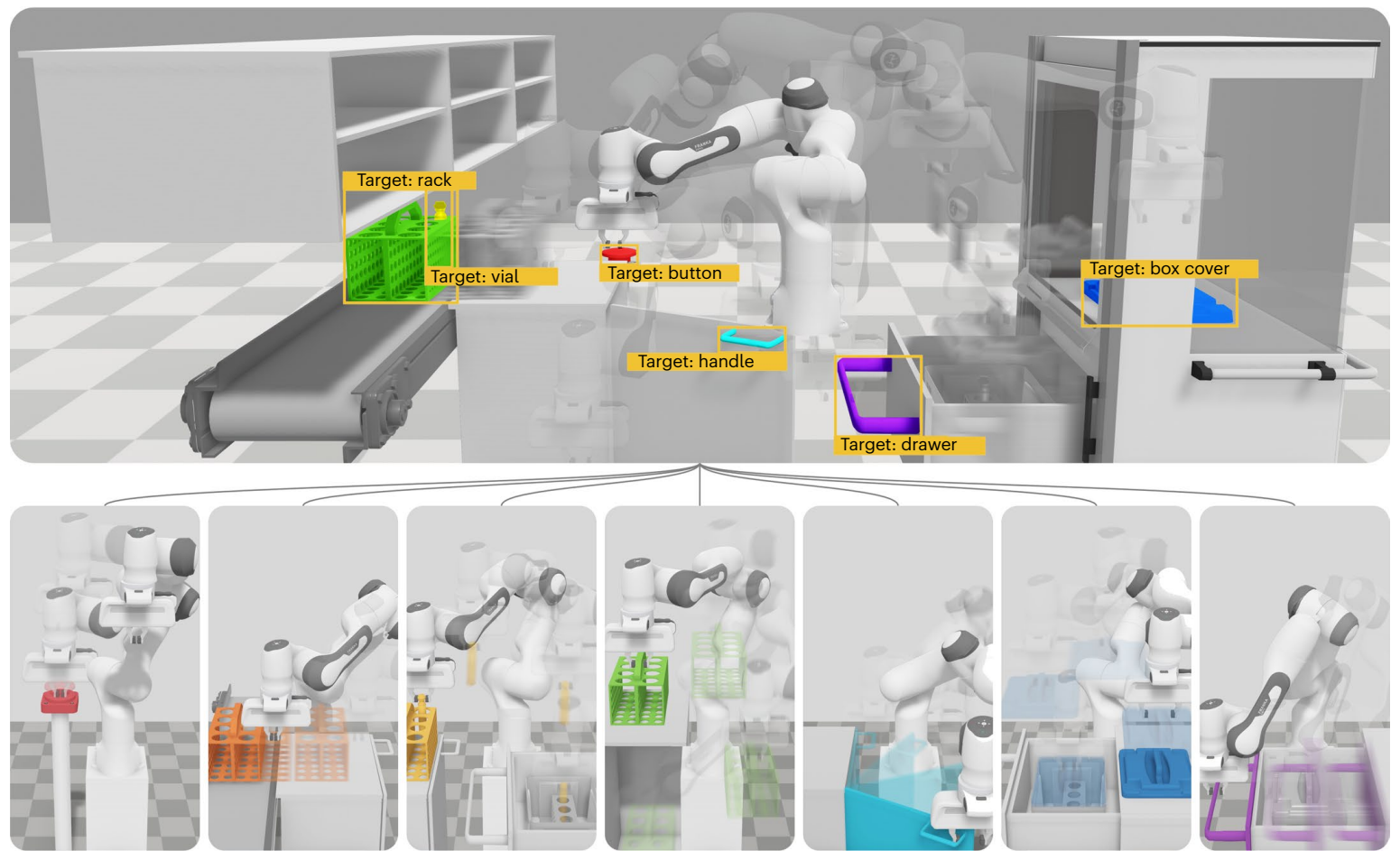
当涉及到与稀疏奖励相关的复杂任务时,Hierarchical Learning(HL) 提供了多种好处,因为它允许将任务分解为更容易接近的问题,即子任务。
- 与 RL 结合:HRL 仍然从根本上依赖于强化学习,因此受到稀疏奖励、复杂规划任务和难以使用先验知识的不利影响。
- 与 IL 结合:当这些 HL 策略应用到 IL(HIL)时,以 teacher–student 的方式能够更容易区分专业专家和获得专业人类技能。
MoEs Architecture #
作者认为,基于 mixture of experts (MoE) 的分层方法能够解决复杂的长期操作任务。
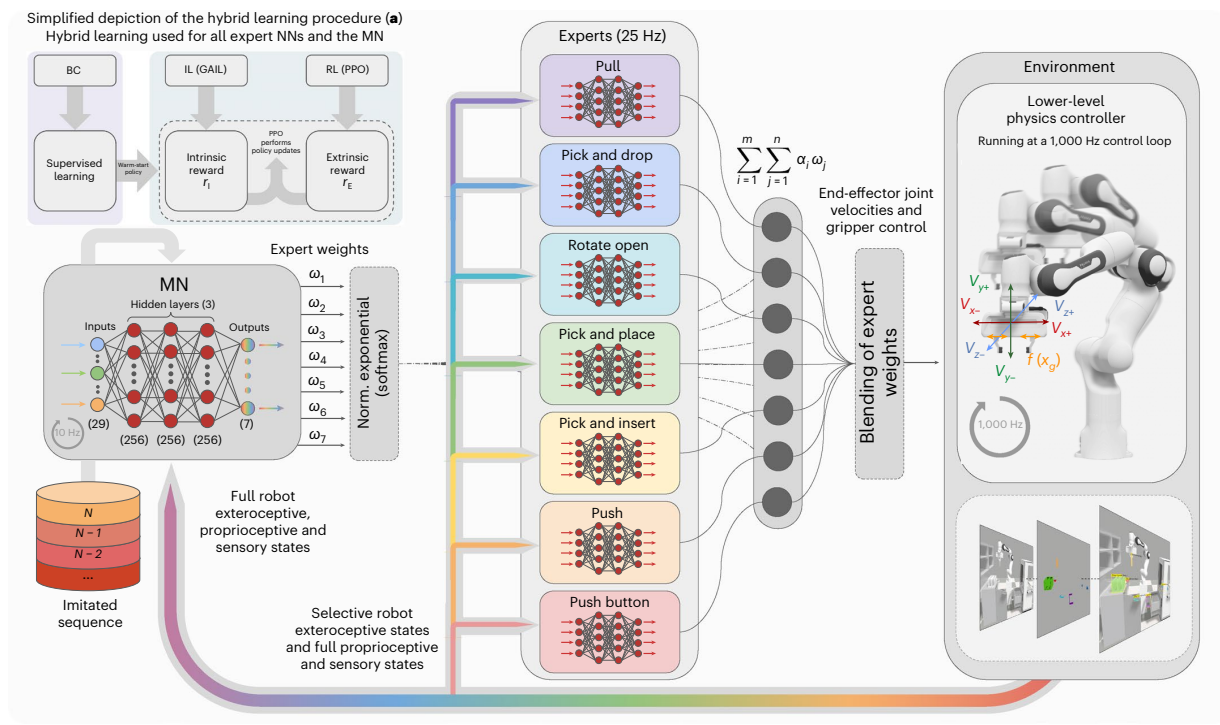
ROMAN 的分层结构如图所示,展示了专家网络是如何协调结合和激活的。每个专家网络是一个多层感知机,专门负责一类基础的操作任务。
作者将 MoE 层中的门网络称为 manipulation network,MN,其训练用于高级的场景理解和专家的编排,这种方法能够提高对未演示情境的泛化性。此外,该算法通过激活多个专家权值来克服局部最小值,从而增强了算法在求解长期序列任务时的鲁棒性。
MN 能够为专家网络分配权重 (∈(0, 1)),最终的输出为这些专家输出动作的加权和: $$ \sum_{i=1}^m\sum_{j=1}^n \alpha_iw_j $$ 每个专家全部数量 (m = 4)的动作 (αi) 由一组与该层次中专家总数(n = 7)相对应的权重 (wj) 控制。我们要确保所有权重的总和不超过1,使用 softmax 函数 σ 对由 MN 分配的权重总和归一化。 $$ σ(z)_i =\frac{e^{z_i}}{\sum^K_{j=1} e^{z_i}} \medspace for\medspace i = 1,…, K\medspace and\medspace z =(z_1,…, z_K)∈ℝ^K $$ 输入 z 表示权重向量,每个元素表示每个专家的权重,K = 7,代表所有7个不同的专家。
Training Procedure #
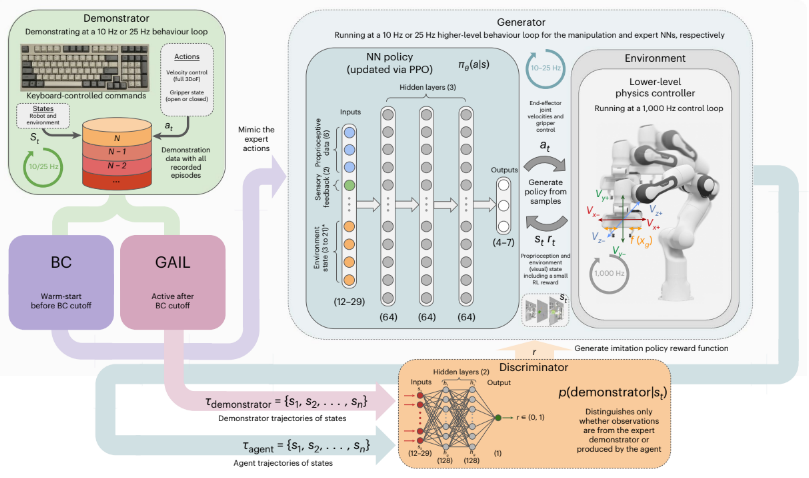
ROMAN 的训练过程由两个阶段组成:
1. 使用 BC 热启动策略。 #
因为 BC 受限制于所看到的演示,无法泛化到超出分布范围的状态,导致当智能体鼓励不在所提供演示内的新轨迹时出现误差。因此,最好不独立地使用 BC,以允许智能体探索更多的样本,改进已演示的行为,同时保持较小的演示数据集。同时在计算与 BC loss 相对应的单独 RL 梯度时添加奖励项。
作者在工作中实现 BC 的方法是,使用由演示提供的 state-action 数据集,通过监督学习去最小化期望动作和实际动作间的均方误差来训练一个 NN 策略。
2. 通过 PPO 算法更新策略,分别使用来自环境(RL)和 判别器(discriminator) network (GAIL) 的 $r_E$ 和 $r_I$。 #
为了有效地匹配一段 horizon 内的演示数据,作者在 BC 的 cutoff point 后又使用了一种逆强化学习方法——GAIL 进行后面的训练,以最小化智能体策略和 demonstrator 间的差异。然而 GAIL 没有直接用于更新策略的参数,作者使用了从 GAIL 中获得的代理模仿奖励信号。
接下来介绍具体的实现方法。首先从演示数据集中采样专家轨迹 $\tau_E$,从生成器 $G$ 中采样智能体轨迹 $\tau_A$。然后由判别器 $D$ 进行打分来给出奖励。$D$ 也是由一个独立的 NN 实现的,如果专家轨迹和智能体轨迹的差异减小,则奖励 $G$ 。 判别器会被训练得越来越严格,使智能体能够更好地模仿人类专家所演示的行为。可以表示成下面的公式: $$ E_{τ_E} [∇ log(D(s_t, a_t))] + E_{τ_A} [∇ log(1 − D(s_t, a_t))] $$
$E_{τ_E}$ 和 $E_{τ_A}$ 作为 $D$ 网络的输入,输出一个 0 和 1 之间的连续值,越接近 1 意味着智能体或生成器的轨迹越接近专家。本质上是最小化差异、最大化模仿。因此,$D$ 可以用作于一个内部奖励信号来训练 $G$ 去模仿专家的演示数据。
此外,为了使智能体进一步探索与所演示的操作相比可以提高性能的其他操作。作者仅令判别器使用演示轨迹中的 state($s_t$),这会导致更多的探索,并将鼓励在与强化学习相结合的情况下做出在演示序列之外的行为。上式可以改写为 $$ E_{τ_E} [∇ log(D(s_t))] + E_{τ_A} [∇ log(1 − D(s_t))] $$ 这可能会使智能体无法进一步探索其他动作,但实际上可能导致基于状态空间的更好的适应,避免对相同模仿的简单复制。
此外,作者还引入了一个小的任务相关的外部奖励信号,以避免最终策略仅依赖模仿,有能力适应新的示例。作者使用内部(来自IL)和外部任务相关奖励来更新策略,其中IL奖励按最高权重缩放,并按程度作为主要学习信号提供者。这允许 ROMAN 在最复杂的专家序列激活期间从局部最小值恢复,即使序列没有精确激活或个别专家出现错误。PPO 的策略网络权重在第 k 步更新的公式为 $$ θ_{k+1} = \underset{θ}{arg max}\mathbb{E}_{s,a\sim {\pi_θk}} [L(s, a, θ_k, θ)] $$
Integration of BC, GAIL and RL. #
为了学习使用有限的演示数据来解决长且复杂的顺序任务,作者通过使用奖励项 rI 和 rE 集成了上述算法,以在探索和利用之间取得有效的平衡。
内部奖励项定义为 $r_I=−log(1−D(s_t)), D(s_t) \in (0, 1)$,作为一个代理奖励项被PPO用来最大化GAIL目标。当训练GAIL和RL时,奖励可以组合为 $ r = r_Iw_I + r_Ew_E$,$w_I$ 和 $w_E$ 是固定的奖励缩放参数,由于作者提出的 HHL 更多关注于 IL,因此 $w_I > w_E$。奖励 r 用于 PPO 策略更新。
每个专家的NN结构和门控网络MN如图所示。从环境中提供给每个 NN 的观测信息是由每个专家的目标以及该信息与成功完成给定子任务的相关性决定的。相比之下,MN观察的是整个环境。
Demonstration acquisition and settings #
关于仿真中物体信息的获取:作者没有直接从仿真中读取物体信息,而是在仿真中加入 RGB 相机来预测感兴趣物体的位姿(OIs)。
- 第一类演示被提供给专家网络(N = 20),包括机械臂末端的速度和夹爪的二进制状态(开或关)。专家网络共享相同的动作,专注于不同的操作技能。
- 第二类演示被提供给 MN(N = 42,7 个场景,每个场景 6 个演示),给定预训练的专家网络,演示包括专家的权重分配。因此,专家演示是针对每个专家的专业技能和目标的,这使得这些预训练的网络可以通过MN演示的顺序来协调,从而连续激活任务。
参考文献 #
- Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
- 知乎-MoE: 稀疏门控制的专家混合层
- Triantafyllidis, Eleftherios, et al. “Hybrid hierarchical learning for solving complex sequential tasks using the robotic manipulation network ROMAN.” Nature Machine Intelligence 5.9 (2023): 991-1005.