1. 前言 #
对于人类来说,最初的动作都是在婴儿时期模仿大人的行为习得的。而对机器人来说,想要让它学习人类动作,也需要从模仿开始。其实,平常的机器人示教操作,就是一个初步的模仿过程。我们通过人工示教,来引导机器人做出相应的动作,即技能的学习。
当今,示教操作主要分为三类,分别是直接动觉示教(Kinematics Teaching)、遥操作示教(Teleoperation)和视频演示示教(Learning from Video)。下面使用机械臂来举例说明:
- 直接动觉示教:手动拖动机械臂,让其记忆拖动点位
- 遥操作示教:使用手持设备或VR技术,远程操作机械臂,记忆过程中的数据流
- 视频演示示教:通过对视频的特征提取,让机械臂学习相应动作
其中,视频演示示教最为自然,但模仿难度更大,因为它属于间接示教,涉及到复杂的人机解耦问题,是近年来的研究热点,也是本篇文章主要的探讨方向。
2. 模仿学习发展历程 #
下图是近年来模仿学习方法的演变过程,图片来自 OpenDILab 的分享https://www.bilibili.com/video/BV1AZ4y1e7WP。图中从上到下是模仿学习方法的主要发展过程,从左到右是某一方法在某一方面的深入。
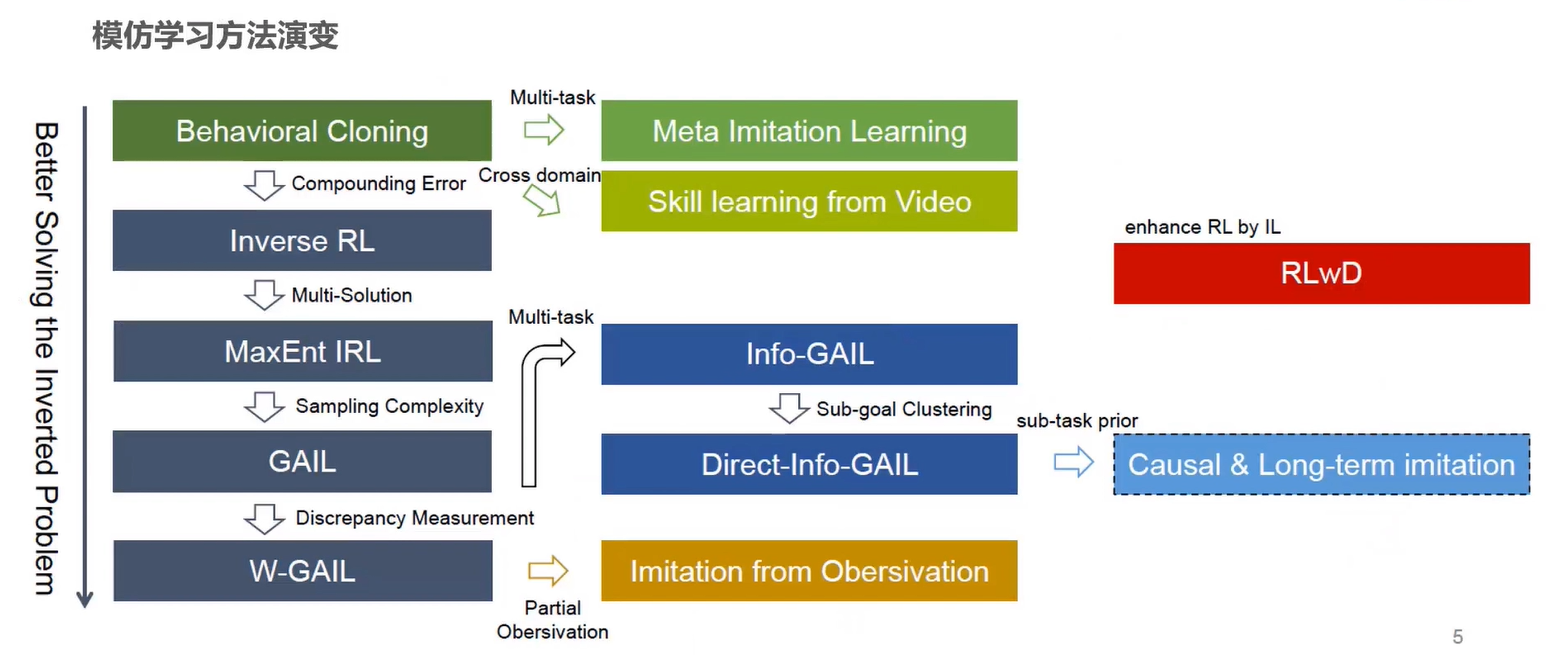
逆强化学习(Inverse RL,IRL):IRL 与 RL 相比,它没有奖励函数,只有环境和专家示范。在训练的时候,智能体可以与环境交互,但它得不到奖励,它的奖励函数必须从专家示范中反推出来(这也是 IRL 要解决的关键问题)。接下来,再使用 RL 的方法学习出最优演员。

逆强化学习总体上可以归结为两类:基于最大边际的逆强化学习和基于概率模型的逆强化学习。
最大边际逆强化学习(Maximum Margin IRL):在早期,IRL 使用最大边际形式化的思想来反推奖励函数。其缺点是经常有很多不同的奖励函数导致相同的专家策略,在这种情况下,所学到的奖励函数往往具有随机的偏好。所以该方法无法解决歧义的问题,这里就不对该方法进行过多讨论。
参考文章:
- https://zhuanlan.zhihu.com/p/26682811
- https://zhuanlan.zhihu.com/p/26766494
- https://zhuanlan.zhihu.com/p/30210839
最大熵逆强化学习(Maximum Entropy IRL,MaxEnt IRL):为了解决最大边际逆强化学习中的多解问题,学术界把目光逐渐转变到基于概率模型的方法上,如最大熵逆强化学习、深度逆强化学习等。
最大熵原理是指,在学习概率模型时,在所有满足约束的概率模型(分布)中,熵最大的模型是最好的模型。这是因为,通过熵最大所选取的模型,没有对未知分布做任何约束或假设。
现在,基于现有的理论,我们已经能够生成较好的模型了,但目前仍存在一个问题,即训练的时候需要投入大量的专家示范供模型学习。
参考文章:
- 最大熵逆强化学习:https://zhuanlan.zhihu.com/p/91819689
- 最大熵逆强化学习实现:https://zhuanlan.zhihu.com/p/95465350
生成对抗模仿学习(Generative Adversarial Imitation Learning,GAIL):该算法类似于 GAN 与 IRL 的结合,以 Maximum Causal Entropy IRL 作为研究的基础框架,解决了逆强化学习计算成本⾼,学习效率低下的问题。
我们可以比较一下逆强化学习与生成对抗网络。如下图所示,在生成对抗网络里,我们有一些很好的图、一个生成器和一个判别器。一开始,生成器不知道要产生什么样的图,它就会乱画。判别器的工作是给画的图打分,专家画的图得高分,生成器画的图得低分。生成器会想办法让判别器也给它画的图打高分。整个过程与逆强化学习是一模一样的。专家画的图就是专家示范,生成器就是演员,演员与环境交互产生的轨迹其实就等价于生成器画的这些图。然后我们需要学习的奖励函数就相当于判别器。奖励函数要给专家示范打高分,给演员与环境交互的轨迹打低分。接下来,演员会想办法,从已经学习出的奖励函数中得到高分,然后迭代地循环下去。

参考文章:
- 原文地址:https://papers.nips.cc/paper/6391-generative-adversarial-imitation-learning.pdf
- https://zhuanlan.zhihu.com/p/354572550
- 例子源自《Easy-RL》:https://github.com/datawhalechina/easy-rl
生成对抗模仿学习(Wasserstein GAIL,W-GAIL) :
将 Wasserstein 距离 与 GAIL 结合,类似于 Wasserstein GAN,实现差异测量,即在训练过程中有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表 GAN 训练得越好,代表生成器产生的图像质量越高。
参考文章:
- Wasserstein GAN 中文:https://zhuanlan.zhihu.com/p/25071913
- WGAN 原文:https://arxiv.org/abs/1701.07875
- http://multimedia.whu.edu.cn/index.php?a=show&catid=72&id=195&lang=1
3. AI动作捕捉 #
从第一节中,我们总结了视频演示示教是机器模仿领域未来的主要发展方向。由于它属于间接示教,并且我们的专家数据通常来自于第三人称视角,而对于机器人来说,任务是在第一视角下进行的。所以,我们如何把第三人称的专家数据泛化到第一人称,以及对 2D 视频流中 3D 信息的实时特征提取,成为目前研究的主要问题。
对于第三人称视角模仿学习,我们可以引入领域对抗训练(domain adversarial training)的概念。领域对抗训练也是一种生成对抗网络的技术。如图所示,我们希望有一个特征提取器,使两幅不同领域(即不同视角)的图像通过特征提取器后,无法分辨出图像来自哪一个领域(即使智能体在第三人称的时候与它在第一人称时的视角是一样的),就是把最重要的特征提取出来。

无论使用哪种方法去处理,其实都是基于分层的思想去做的。首先是一个表征学习的过程,我们把视频流中的环境信息通过特征提取器提取出来。之后,再使用提取出的特征信息作为专家示范去学习。
对于双臂机器人的轨迹规划问题,在这里提出了两个场景。
场景一:动作捕捉。近年来,元宇宙的概念逐渐被炒得火热,虚拟主播(vtuber)这一行业也正在加速发展,实时动作捕捉技术自然成为虚拟现实领域当下的研究热点之一。其中,实时动捕主要分为两个研究方向:面部动捕与全身动捕,然而我们主要关注全身动捕的一部分——双臂动捕。
实际上,我们所拍摄的人体动作视频数据,提取出的是人体的关节信息,如何把人体关节信息及其运动轨迹泛化到机器人身上,使机器人在模仿人类动作的同时,保持轨迹的平滑,是一个值得思考的问题。一种方法是,使用学习的方法去优化轨迹。


场景二:物体交互。物体交互技术是基于动作捕捉的进一步发展,我把它分为三个方面:虚拟交互、现实交互和虚拟现实交互。虚拟交互是完全在虚拟场景中的交互,例如游戏或仿真软件内的人机交互等。现实交互是在真实场景中的交互,如机器人与真实物体的交互。虚拟现实交互是现实的人与虚拟的物品的交互,如 VR 中的力反馈效果。
当然,这里只讨论双臂与物体的交互。在现实交互中,双臂相较于单臂,有更多的对象参与到交互中,因此具有更高维的动作-状态空间、更高范围的解。目前多数的双臂问题都使用经典的控制方法来解决,但很难用于泛化的环境中。因为在交互中,两臂与物体间会产生摩擦、粘附和变形,这些变化很难明确且精准地表示出来。那么一种有效的方法就是模仿学习,我们为机器人提供人类行为的演示,让机器人学习一个策略去模仿人类动作。


4. 展望 #
最后,我们可以将动作捕捉与物体交互结合到一起,让机器人学会许多的人类行为。也就是说,我们可以让机器人看大量的视频,令机器人学会视频中的动作,例如跳舞、做家务等等,从而解放大量的底层劳动者,因为模型是可以迁移和泛化的。或者,也可以用于科幻影视作品的摄制过程。但是,目前的主要问题集中在算法稳定性的提升上,将经典的控制算法与机器学习深度融合,提高算法的可解释性,是一个推荐的方向。