前言 #
最近花了一些阅读和复现 Relay Hindsight Experience Replay(RHER) 算法,这篇文章写的非常扎实,但作者开源的代码是基于 tensorflow 的 baselines 框架编写的。我在使用 pytorch 重写的过程中有了一些心得体会,在这分享出来。
RHER 的 GITHUB 链接:https://github.com/kaixindelele/RHER
我自己使用 pytorch 复现的 GITHUB 链接:https://github.com/NoneJou072/rl-notebook
非常感谢作者的工作。
复现过程 #
issue-1 #
作者在 baselines 中的更新策略的方法是,按顺序分别训练 push 子任务和 reach 子任务。在 issue-5 中也提到了 每次更新当前的,以及下一个任务的策略函数。但在我的复现过程中发现,这样会出现 灾难性遗忘,当更新下一个任务的策略时,上一次被更新的任务会被遗忘掉。
但是作者又在 issue 中回答到:
不能存轨迹,而是每次交互后,先目标重标记,再把所有的子任务的数据,分别存到对应的经验池中。
论文中也提到:
对于三物体任务,需要更新先前的部署细节:1)使用基于PyTorch的双延迟DDPG(TD3)方法[47],而不是基于TensorFlow的DDPG方法。
对于基于PyTorch框架的多物体操作任务,在每收集一次轨迹后需要立即重新标记,并将多个子任务的transition,分别存储在不同的经验池中。在每次更新时,样本独立收集,然后组合成一个完整的批次。
一个令我比较疑惑的点是,为什么三物体不接着延续基于 tensorflow 的 baselines 框架,为什么使用 baselines 框架时按顺序更新策略函数不会出现遗忘问题。
reproduction-1 #
于是,我使用 pytorch 的 DDPG 方法,按照上述的描述进行了修改,并加入了一些我自己的调整,大概的伪代码为
- 分别为 push 和 reach 子任务创建两个经验池
- 与环境交互,得到一个 episode 的 transitions
- 回合结束后,分割出当前 episode 属于 reach 子任务的 transitions。之后分别将轨迹存到对应的经验池中。
- 策略更新时,分别从两个经验池中采样,然后组合成一个完整的批次。
issue-2 #
使用基于 pytorch 编写的 DDPG 方法进行训练时,发现奖励函数的值会先抵达 0.8 左右的成功率,之后便会降低到 0.4 左右。
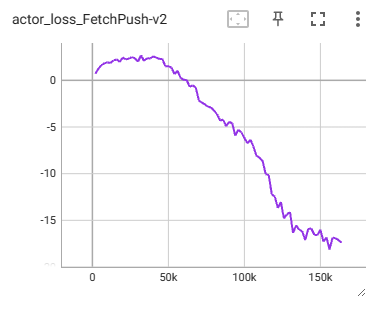
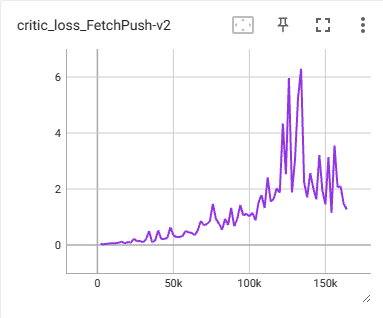
在 DDPG 中,actor loss 表示负的 Q 值,actor loss 越小,Q 值越大。此时 actor loss 呈现出很大的下降趋势,critic loss 呈现很大的震荡。明显是出现 Q 值被高估的情况了。
为什么会有Q值高估问题出现?-> 曾伊言: 强化学习算法TD3论文的翻译与解读。
由于 Q 值过大,会导致时序差分目标 q_targets 过大
参考自 Y. F. Zhang: 一个AC类算法策略loss引出的思考
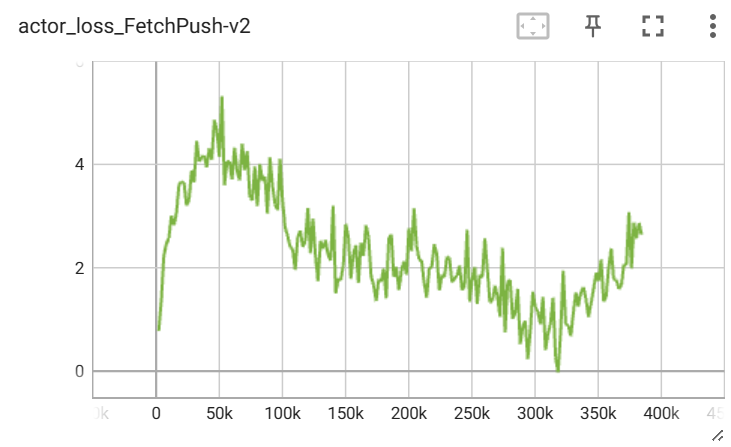
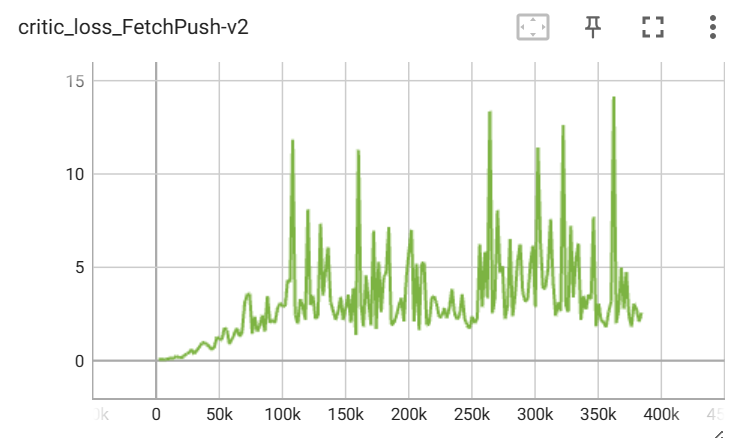
结果对比 #
下面是作者在 FetchPush-v1 环境下的结果:

下面是我在 FetchPush-v2 环境下的复现结果:
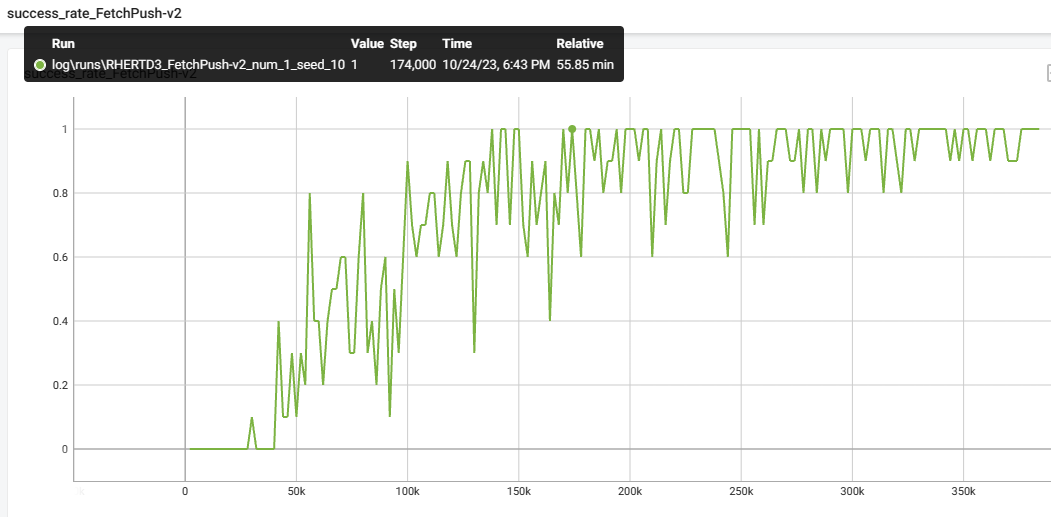
可以看到,在训练时间 56min 左右时,成功率稳定在了 95% 左右,与作者的结果相差不大。