折扣因子 discount factor - gamma #
Reference: 曾伊言-深度强化学习调参技巧:以D3QN、TD3、PPO、SAC算法为例
这个值的含义是“你希望你的智能体每做出一步,至少需要考虑接下来多少步的reward?”如果我希望考虑接下来的t 步,那么我让第t步的reward占现在这一步的Q值的 0.1,即公式 $0.1\approx\gamma^t$,变换后得到:$\gamma\approx 0.1^{1/t}$
gamma ** t = 0.1 # 0.1 对于当前这一步来说,t步后的reward的权重
gamma = 0.1 ** (1/t)
t = np.log(0.1) / np.log(gamma)
0.9 ~= 0.1 ** (1/ 22)
0.96 ~= 0.1 ** (1/ 56)
0.98 ~= 0.1 ** (1/ 114)
0.99 ~= 0.1 ** (1/ 229)
0.995 ~= 0.1 ** (1/ 459)
0.999 ~= 0.1 ** (1/2301) # 没必要,DRL目前无法预测这么长的MDPs过程
可以看到 0.96, 0.98, 0.99, 0.995 的gamma值
分别对应 56, 114, 229, 459 的步数
调整 gamma 的意义在于加速收敛。如果 gamma 过于大,意味着越多考虑未来的奖励,而未来的不确定性更多,超出了智能体所能掌控的范围。 gamma绝对不能选择1.0,gamma等于或过于接近1会有“Q值过大”的风险。一般选择0.99,在某些任务上需要调整。 而如果 gamma 选的很小,智能体只会关注短期回报,可能导致陷入局部最优。
动图是 LunarLander任务,悬空状态下会得到一些一般在 ±5之间的 reward。降落后会一次性得到 +100的reward(下图(a)、(b)的黄色曲线 Reward Success, 在400多步)或者坠毁一次性扣-100(下图(b)的淡蓝色曲线 Reward Failure,在300步左右)。 你希望智能体预见到多少步之后的 降落、坠毁事件?
下图(a) 展示了一次成功降落的结果在不同 gamma值下的表现。横坐标是第t步,纵坐标是第t步的Q值。我把贝尔曼公式 $Q_t=r_t+\gamma Q_{t+1}$ 写成求和的形式 $Q_t=\sum_t\gamma^{t-1}r_t$。当 $\gamma \to 1$ 时,有偏红曲线 $Q_t=\sum_t\gamma^{t-1}r_t$。当 $\gamma \to 0$ 时,有偏黄曲线 $Q_t\to r_t$ 。
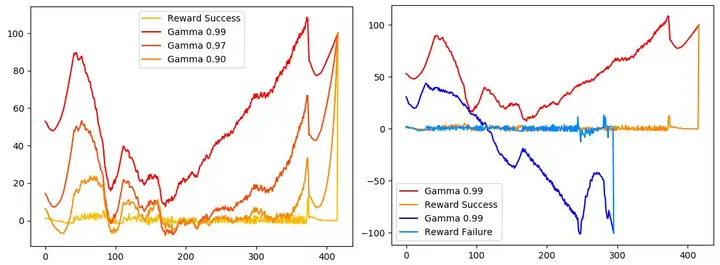
从(a)观察到,gamma=0.99的曲线在200多步时曲线斜率明显增加,说明提前200步“预测”到安全降落的事件,而gamma=0.97和0.9曲线分别在300和400多步时才明显增加(在这之前斜率上升的原因是400步之前有一段奖励较高),因此gamma=0.99比较合适。
从右图(b)观察到,在 gamma=0.99 时,深蓝线在第150步预测到的Q值已经很小,预示着约150步后会坠毁。深红线在第350步预测到Q值已经很大,预示着约150步后能平稳降落。 所以在这个环境,把gamma定为0.99 可以让智能体预见到 150步以后的事件。事件发生后会得到一个比 日常reward 大得多的 结算reward,在这里 日常reward 是结算reward的0.05倍。游戏结束在第t 步结束时,结算reward $r_t$ 可能是±100。
而在基于时序差分的RL方法中,我们通常拟合神经网络 $\theta$ 来预测下一时刻的Q值 $Q_{t+1}=\theta(s_{t+1},a_{t+1})$,用来计算时序差分目标 $Q_{target} = r_t + \gamma Q_{t+1}$.